
O novo Gemini 1.5 Flash
Durante o Google I/O 2024, a conferência para programadores, que é organizada anualmente pela Google em São Francisco, Califórnia (US), foram anunciadas diversas novidades de produtos, dentre estas novidades está a disponibilização do Gemini 1.5 Flash.
O Gemini 1.5 Flash tem uma janela de contexto de um milhão de tokens por padrão, o que significa que você pode processar uma hora de vídeo, 11 horas de áudio, bases de código com mais de 30.000 linhas de código ou mais de 700.000 palavras.
Vamos modelar?
Nossa aplicação web visará auxiliar na alfabetização e no desenvolvimento da linguagem de pessoas em situação de vulnerabilidade, oferecendo ferramentas de consulta de significados de palavras, transcrição e análise de áudio, e dicas para aprimorar a fala.
Pensando na aplicação web utilizaremos Cloud Functions, que permite o acionamento do código no Google Cloud, Firebase e Google Assistente, ou o chame diretamente de qualquer aplicativo da Web, de dispositivos móveis ou do back-end via HTTP.
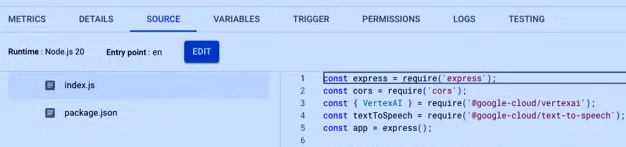
Utilizaremos a trigger HTTP, e dentro da function navegaremos até o menu “source”, onde iremos desenvolver a integração e modelar a Gemini 1.5 Flash, utilizaremos NodeJS e Express.
Vamos para o código!
1. Importações de Módulos e Configurações Iniciais:
const express = require(‘express’);
const cors = require(‘cors’);
const { VertexAI } = require(‘@google-cloud/vertexai’);
const textToSpeech = require(‘@google-cloud/text-to-speech’);
const app = express();
- Este bloco importa os módulos necessários para o funcionamento do aplicativo.
- Express é um framework web para Node.js que simplifica a criação de aplicativos web.
- ‘cors’ é um middleware do Express para habilitar o Cross-Origin Resource Sharing (CORS).
- VertexAI e textToSpeech são APIs do Google Cloud para inteligência artificial e síntese de fala, respectivamente.
- ‘app’ inicializa uma instância do Express.
2. Configuração dos Clientes da API do Google Cloud:
const client = new textToSpeech.TextToSpeechClient();
const vertex_ai = new VertexAI({ project: ‘chat-ai-416220’, location: ‘southamerica-east1’ });
const model = ‘gemini-1.5-flash-preview-0514’;
- Neste bloco, são configurados os clientes para acesso às APIs do Google Cloud.
- ‘client’ é configurado para acessar a API de Text-to-Speech.
- ‘vertex_ai’ é configurado para acessar o Vertex AI (uma plataforma de IA do Google Cloud).
- ‘model’ especifica o modelo de geração de texto a ser utilizado.
3. Configuração de Modelo Generativo:
const generativeModel = vertex_ai.preview.getGenerativeModel({
model: model,
generationConfig: {
‘maxOutputTokens’: 8192,
‘temperature’: 1,
‘topP’: 0.95,
},
safetySettings: [
{
‘category’: ‘HARM_CATEGORY_HATE_SPEECH’,
‘threshold’: ‘BLOCK_MEDIUM_AND_ABOVE’
},
{
‘category’: ‘HARM_CATEGORY_DANGEROUS_CONTENT’,
‘threshold’: ‘BLOCK_MEDIUM_AND_ABOVE’
},
{
‘category’: ‘HARM_CATEGORY_SEXUALLY_EXPLICIT’,
‘threshold’: ‘BLOCK_MEDIUM_AND_ABOVE’
},
{
‘category’: ‘HARM_CATEGORY_HARASSMENT’,
‘threshold’: ‘BLOCK_MEDIUM_AND_ABOVE’
}
],
});
- Neste bloco, estamos configurando o modelo generativo a ser usado para gerar texto.
- ‘vertex_ai.preview.getGenerativeModel()’ é um método que obtém um modelo generativo específico da Vertex AI.
- ‘model’ é o nome do modelo que será utilizado.
- ‘generationConfig’ define as configurações de geração de texto, como o número máximo de tokens de saída, a temperatura e o top-p.
- ‘maxOutputTokens’ especifica o número máximo de tokens (ou palavras) no texto de saída.
- ‘temperature’ controla a aleatoriedade das previsões do modelo durante a geração.
- ‘topP’ define a probabilidade cumulativa das previsões de tokens, limitando o conjunto de tokens possíveis.
- ‘safetySettings’ são configurações de segurança para filtrar conteúdo prejudicial.
- Cada configuração dentro de ‘safetySettings’ especifica uma categoria de conteúdo prejudicial e um limite de segurança.
- Por exemplo, ‘HARM_CATEGORY_HATE_SPEECH’ representa discurso de ódio e ‘BLOCK_MEDIUM_AND_ABOVE’ significa que o modelo deve bloquear conteúdo de nível médio e superior de discurso de ódio.
Este bloco garante que o modelo generativo seja configurado com as especificações desejadas e com medidas de segurança para filtrar conteúdo prejudicial.
4. Middleware e Configuração do Express:
app.use(cors());
app.use(express.json());
- Estes são middlewares do Express.
- ‘cors()’ permite solicitações de diferentes origens (cross-origin).
- ‘express.json()’ analisa solicitações com dados JSON no corpo da solicitação.
5. Prompt para Geração da explicação com Tema:
app.post(‘/theme’, async (req, res) => {
const body = req.body;
const input = body.theme;
const prompt = { text: `Não conheço a lingua portuguesa e gostaria de entender o significado da palavra ${input} de forma simples e didatica ` };
const request = {
contents: [
{ role: ‘user’, parts: [prompt] }
],
};
try {
const streamingResp = await generativeModel.generateContentStream(request);
const response = await streamingResp.response;
res.json(response);
} catch (err) {
console.error(‘ERROR:’, err);
res.status(500).json({ error: ‘Error generating text’ });
}
- Esta parte do código define uma rota POST acessível em ‘/theme’.
- Quando uma solicitação POST é feita para ‘/theme’, esta função assíncrona é acionada.
- ‘req.body’ contém os dados enviados no corpo da solicitação POST.
- ‘const input = body.theme’ extrai o tema enviado na solicitação POST.
- ‘const prompt’ é um objeto que contém um texto de prompt para solicitar a geração de um texto curto.
- O texto do prompt é construído usando interpolação de string para incluir o tema fornecido na solicitação.
- ‘const request’ é um objeto que contém os detalhes da solicitação que será enviada para o modelo generativo.
- ‘contents’ é uma matriz de objetos que representam o conteúdo a ser gerado.
- No caso, há apenas um objeto com role definido como ‘user’ e ‘parts’ contendo o prompt definido anteriormente.
Essencialmente, este trecho prepara os dados necessários para solicitar ao modelo generativo que gere um texto curto sobre um determinado tema, com base no tema fornecido na solicitação POST.
6. Prompt para Geração de Resposta de Áudio:
app.post(‘/audio’, async (req, res) => {
const body = req.body;
const input = body.audio;
const prompt = { text: ‘Você é um professor de lingua portuguesa(Braisl), corrija a forma que formulei minha frase se ouver algum erro, e mostre os pontos que posso melhorar’ };
const request = {
contents: [
{ role: ‘user’, parts: [input, prompt] }
],
};
try {
const streamingResp = await generativeModel.generateContentStream(request);
const response = await streamingResp.response;
res.json(response);
} catch (err) {
console.error(‘ERROR:’, err);
res.status(500).json({ error: ‘Error generating text’ });
}
});
- Quando uma solicitação POST é feita para ‘/áudio’, esta função assíncrona é acionada.
- ‘req.body’ contém os dados enviados no corpo da solicitação POST, e ‘const input = body.audio’ extrai o áudio da solicitação.
- ‘const prompt’ é um objeto que contém um prompt de texto para guiar a geração da resposta de áudio. Este prompt é definido manualmente.
- ‘const request’ é um objeto que contém os detalhes da solicitação que será enviada para o modelo generativo. Ele inclui o áudio de entrada e o prompt.
- Dentro do bloco try, a função ‘generativeModel.generateContentStream(request)’ é chamada para gerar o conteúdo com base na solicitação preparada anteriormente.
- ‘const response = await streamingResp.response;’ aguarda a resposta do fluxo de dados gerado pela chamada ‘generativeModel.generateContentStream(request)’.
- Finalmente, ‘res.json(response);’ envia a resposta gerada de volta ao cliente como uma resposta JSON.
Se ocorrer algum erro durante a geração de texto, o bloco catch será executado, registrando o erro no console e enviando uma resposta de status 500 com uma mensagem de erro JSON para o cliente.
7. Prompt para Síntese de Texto para Áudio:
app.post(‘/synthesize’, async (req, res) => {
const body = req.body;
const input = body.text;
const inputText = {
text: input
};
const voice = {
languageCode: ‘pt-BR’,
name: ‘pt-BR-Standard-A’,
};
const audioConfig = {
audioEncoding: ‘LINEAR16’,
speakingRate: 1,
};
const request = {
input: inputText,
voice: voice,
audioConfig: audioConfig,
};
try {
const [response] = await client.synthesizeSpeech(request);
const audioContent = response.audioContent;
res.setHeader(‘Content-Type’, ‘audio/mpeg’);
res.json(audioContent);
} catch (err) {
console.error(‘ERROR:’, err);
res.status(500).json({ error: ‘Error synthesizing audio’ });
}
});
exports.en = app;
8. Utilizando Bibliotecas:
Para utilizar bibliotecas dentro do Cloud Fuctions basta criar um package.json
Código package.json:
{
“dependencies”: {
“express”: “^4.18.2”,
“cors”: “^2.8.5”,
“@google-cloud/vertexai”: “^1.1.0”,
“@google-cloud/text-to-speech”: “^5.2.0”
}
}
E assim modelamos um modelo multimodal!
Pronto para os próximos?
No dia de hoje, 16 de maio de 2024, o modelo Gemini 1.5 Flash está em fase de preview, porém já está disponível no console do GCP (Google Cloud Platform), revelando-se um modelo com um potencial significativo no processamento de dados, como demonstrado na tabela abaixo:
Em conclusão, seja qual for o modelo escolhido, todos eles permitem que o foco de um projeto esteja nas soluções que são viáveis para resolver problemas reais.
| Capacidade | Referência | Descrição | GEMINI 1.0 PRO | GEMINI 1.0 ULTRA | GEMINI 1.5 PRO(Feb 2024) | GEMINI 1.5 FLASH |
| Em geral | MMLU | Representação de questões em 57 disciplinas (incluindo STEM, humanidades e outras) | 71.8% | 83.7% | 81.9% | 78.9% |
| Código | Natural2Code | Geração de código Python. Distribuído conjunto de dados semelhante ao HumanEval, não vazado na web | 69.6% | 74.9% | 77.7% | 77.2% |
| Matemática | MATH | Problemas desafiadores de matemática (incluindo álgebra, geometria, pré-cálculo e outros) | 32.6% | 53.2% | 58.5% | 54.9% |
| Raciocínio | GPQA (main) | Conjunto de dados desafiador de perguntas escritas por especialistas em biologia, física e química | 27.9% | 35.7% | 41.5% | 39.5% |
| Big-Bench Hard | Conjunto diversificado de tarefas desafiadoras que exigem raciocínio em várias etapas | 75.0% | 83.6% | 84.0% | 85.5% | |
| Multilíngue | WMT23 | Tradução de idiomas | 71.7 | 74.4 | 75.2 | 74.1 |
| Imagem | MMMU | Problemas de raciocínio multidisciplinar em nível universitário | 47.9% | 59.4% | 58.5% | 56.1% |
| MathVista | Raciocínio matemático em contextos visuais | 45.2% | 53.0% | 52.1% | 54.3% | |
| Áudio | FLEURS (55 languages) | Reconhecimento automático de fala (com base na taxa de erro de palavras, quanto menor, melhor) | 6.4 | 6.0 | 6.6 | 9.8 |
| Video | EgoSchema | Resposta a perguntas em vídeo | 55.7% | 61.5% | 63.2% | 63.5% |
Por hoje é isso, espero que tenham gostado!
Categories
Entre em Contato
+55 (11) 4839-0225
contato@sauter.digital
Rua Funchal, 375 - 11ºandar Vila Olimpia, São Paulo SP - CEP: 04551-060
Assessoria de Imprensa
+55 (11) 4839-0225
fran@oficina.inf.br
Newsletter
Copyright © 2024 Sauter - 36.569.241 / 0001-01 Todos os direitos reservados. Confira nossa Política de Privacidade